2026/06/01
大模型知识学习
记录自己学习大模型相关知识的笔记
写在前面
学习方法
1、树立信心,战略上藐视
为什么有时候我们会觉得学不懂或者学习某个内容很难?
世界上没有“绝对困难”的内容,只有“简单但不完整”的内容。
所有的概念,本质上都是一个“逻辑链条”,一环接一环。
学习的本质是我们从已知出发,走向未知,而学习的难度正取决于已知与未知间的割裂程度:倘若已知与未知之间是通过一个个紧密相连的中间环节连接的,那每一步都可以轻易到达,最终通过多个简单步骤的叠加,到达未知;倘若已知与未知之间存在大量断裂的环节,我们则需要猜测或补足这些缺失的中间环节,困难就是在这个过程中出现的。
例如从 A 到 C 之间缺失的部分是 B,从 A 到 B 到 C 的逻辑不难,难的是修补 A 和 C 之间断裂的逻辑链条。
因此,所有的概念都是通过大量简单的概念形成“逻辑链条”得到的,我们学习的过程,其实就是不断填补缺失的逻辑链条的过程。所以在学习上受挫时,不要自我怀疑,也不要因此气馁,而应该去补足中间缺失的一个个简单的中间环节。
2、战术上重视
-
提升大脑提取、总结能力:如果是看视频,每 3-5 分钟就回顾总结刚才看的内容;如果是文档,每几页或每个小节就回去总结学的内容。
-
目标粉碎化,获取频繁正反馈:每一小段内容就进行回顾、总结,遇到不能顺利回顾、总结的部分,就倒回去重新学习。完成此过程后落盘为阶段性成果(可以是文档、公式推导、思维导图等),以获得正反馈,然后清空大脑,继续下一个任务。
-
三遍学习法:完整观看视频,抓住整体逻辑脉络,不纠结细节,遇到不懂的点先标记,而是建立全局认知;动手复现代码,培养独立解决问题的能力,目标是“跑通 + 理解每一行代码的作用”;闭卷复述(知识点,录音或白板手写)& 手撕(代码),从“学了”走向“学会了”
3. 学到了什么,远远大于学了什么
看的视频/文档,跟着做的笔记都是学了什么。而脱离视频和文档对所学内容的总结,独立画的思维导图,才是学到了什么。
学习纪律
- 代码必须动手写,动手跑
- 面试题当真题,最好对着镜子/录音,模拟面试状态
- 里程碑小结,每个模块结束后,写“模块小结”,回答:这个模块解决了什么问题?核心思想是什么?和上一个模块的关系是什么?
- 遇到问题自己先解决,培养独立解决问题能力(未来工作最重要竞争力之一)
- 日拱一卒,不要断档
每阶段通关要求
- 思维导图:闭卷复述
- 面试题:脱稿讲解
- 代码手撕:不借助任何工具
阶段一 大模型核心技术
第一讲 NLP 核心技术概念
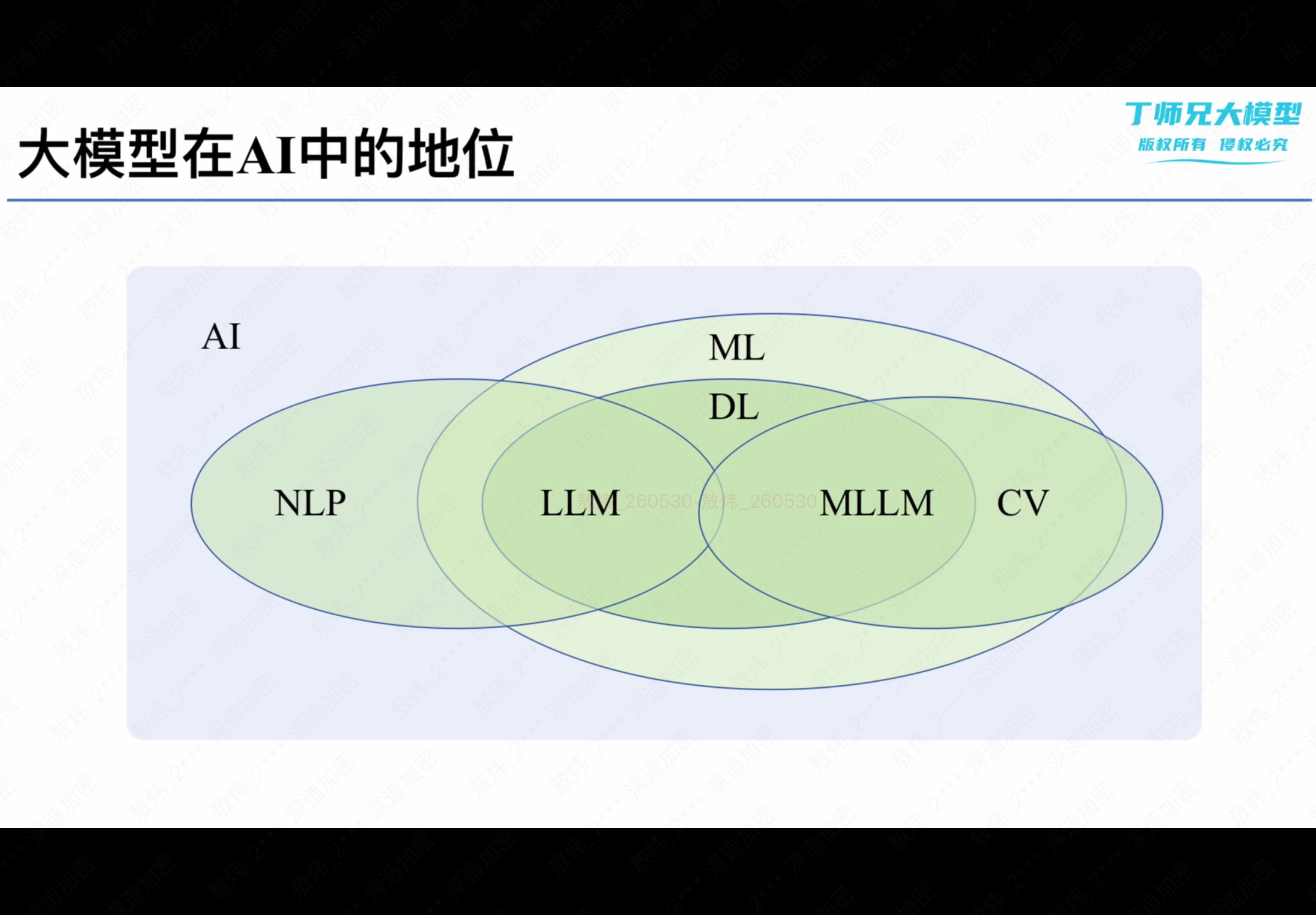
1 大模型在 AI 中的地位
整个 AI 领域现有技术的关系大致如下:
- ML 是 AI 下的一个大分支,其中 DL 又是目前 ML 的主流分支。
- NLP 是一个历史悠久的问题,最早用 ML 和其他非 ML 的 AI 方法来解决,现在主流的解决方案为 DL 分支下提出的 LLM。
- CV 又是另一个历史悠久的问题,最早也用 ML 和其他非 ML 的 AI 方法来解决,现在主流的解决方案为 DL 分支下提出的 NN 方案与 LLM 方案融合所成的 MLLM(多模态大语言模型)方案。
着重介绍一下 MLLM,这是以前没有接触过的概念:
- 可以理解为:LLM + 图像/音频/视频等其他模态输入能力。其中模态是指信息的表现形式,常见模态有:文本、图像、音频、视频、传感器数据。
- 传统的 LLM(如 GPT)最早属于:单模态模型(Text-only),只能处理文字。而 MLLM 则可以处理多种模态的数据。
- 所以 MLLM 和 LLM 的主要区别在于:
LLM MLLM 图片 音频 视频 文字 文字 等 ↓ ↓ LLM MLLM ↓ ↓ 文字 文字 图片 语音 等 - MLLM 的核心结构可简化为
图片 ↓ Vision Encoder: 负责看图,常见的有 ViT、CLIP、SigLIP,作用是将图片转换为数字特征 ↓ 特征向量 ↓ Adapter/Projector:将视觉特征翻译成 LLM 能理解的 Token ↓ LLM ↓ 文字输出
上述技术整体关系图如下图所示
2 什么是语言模型
语言模型是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。最早应用于语音识别问题,语音识别算法在将语音转换为文字时会给出多个候选序列,这个时候就需要用语言模型对候选序列做排序。
所以从概率论的角度来看,语言模型的任务是估计: 即一个词序列出现的概率。也可写成条件概率: 意思为根据前面的词预测下一个词。
那其中的每一个条件概率如何计算呢?根据计算方式的不同,便分为了统计语言模型和神经网络语言模型两大类,以 的计算为例,展示两种语言模型的区别:
统计语言模型
-
对于统计语言模型,上述概率计算过程为
- 如何体现统计性:在具有代表性的大语料库(如维基百科)上进行统计,统计出来的结果可代表真实人类语言;
- (即候选词)的来源:从上述语料库中收集整理所有不重复的词,做成词表(大小几万至几十万不等),词表中的词即可作为候选词;
- 如此计算的依据:核心思想为根据大数定律,当语料库足够大时,可以用词出现频次来估计词出现概率。用表示语料库长度,所以有
-
为了简化条件概率链式法则中长历史条件概率的,统计语言模型通常采用 N-gram 假设,即认为当前词仅与最近 N-1 个词有关。但由于强马尔可夫假设,会直接导致长距离依赖被忽略,即 N-gram 无法建模长距离语义依赖。
-
同时该方法有个明显的问题为数据稀疏导致的零概率问题:若某一合理词序列未在语料库中出现过(即频次为 0),导致概率为 0。为此提出平滑方法以解决该缺点,以拉普拉斯平滑为例,分子频次 + 1,分母频次 + |V|(词表大小)。
-
总的来说,统计语言模型有如下几个难以克服的问题存在:
- 长距离依赖被忽略
- 高阶 N-gram 的参数量呈指数级爆炸增长,组合空间爆炸,绝大多数词组合从未出现,导致数据极度稀疏,进而导致的零概率问题
- 由于指数级爆炸增长的参数量,进而导致存储和计算复杂度极高
- 容易出现过拟合,如 和 均只在语料库中出现过一次,则 ,将偶然事件当作必然事件,无法输出其他有意义的词序列
- 泛化能力差,完全基于“记忆”,没有理解,强烈依赖于训练语料库
- 无法处理未登录词(OOV 问题)
- 没有参数共享
神经网络语言模型
- 对于神经网络语言模型,依旧采用 N-gram 假设,但不再采用统计的方法,而是将构建好的模型在语料库上进行训练,此后向模型输入上下文 context,模型输出所有候选词的出现概率。
- 神经网络语言模型训练集的构建:以 N-gram 模型为例,将语料库按长度为 N 的滑动窗口进行切分,每个滑动窗口中前 N-1 个词为模型输入,第 N 个词为模型输出(即标签),据此构建神经网络语言模型的训练集。
- 神经网络语言模型接受输入的方式为:依据输入词 id 在共享词表 C 中进行 look-up,将每个词转换为模型能够处理的词向量。
- 总的来说,神经网络语言模型的整体结构为:输入层、隐藏层、输出层。
3 面试题
一、如何评价一个语言模型好坏?
为评价一个语言模型的好坏,最直接的方式是将其放在应用场景中进行判断,但该方法与应用场景高度绑定,不具有泛化性,且耗时,所以人们设计出一种与应用场景无关的、客观的评价指标:困惑度(Perplexity)。
设有一长度为 的词序列 :
困惑度计算公式如此设计的原因如下,
-
首先明确语言模型在做什么:
一句话 可以写成:
语言模型会给整个句子一个概率:
也就是说: 整句话的概率 = 每一步预测正确词的概率连乘
-
那为什么不能直接用 来评价模型?
因为句子越长,概率连乘越多,而每个概率均小于等于 1,故 天然越小,所以直接比较 不公平,需要将其变成:平均到每个词上的预测难度,所以公式里会有一个
-
为什么是 呢?
这需要拆成两个部分来理解:
-
取 次方根
这表示每个词的平均预测正确概率,因为,所以,这是所有条件概率的几何平均数。
这里为什么用几何平均数,以及几何平均数所代表的含义,可以用这样一个小例子来说明:
首先,因为这里是概率的连乘,所以应该用几何平均,而非算数平均;
假设一句话有 3 个词,每一步预测正确真实词的概率分别为 ,则整句话的概率为 ;
现在我们想找一个“平均概率” ,使其满足 ,即 ,所以 。
由该例子可以看到,取 的 次方根,可以将整句正确预测的概率平均到正确预测每个词上,使得比较与句子长度无关。
-
取倒数
正确预测概率越大时,模型越好;但我们希望困惑度指标越小越好,所以我们取倒数。同时 表示模型平均每一步大概在几个词之间困惑。所以平均正确预测概率越高,困惑度越低;平均正确预测概率越低,困惑度越高,其本质上是
-
-
困惑度和交叉熵的关系
困惑度也可以写作:
其中 exp 中的部分就是平均负对数似然,也就是语言模型常用的交叉熵损失,所以:
具体操作方法为:人为构建一个由代表性词序列组成的测试集,语言模型在该测试集上的困惑度越低,则代表性词序列概率越高,语言模型效果越好。
二、如果神经网络语言模型的词表 V 很大,如何加速训练,避免直接用全量 softmax?
-
首先明确 softmax 操作是将模型原始输出的 logits 转换为和为 1 的概率分布,其具体操作为:
其中:
- 为第 i 个候选词的原始分数;
- 将分数变为正数,确保没有负概率出现;同时放大分数差距,如 ,使原始得分高的词获得明显更大的概率
- 为归一化项
- 为第 i 个词被选中的概率
由此可见:每训练一个样本,都要计算整个词表所有词分数的指数和归一化项,复杂度大约是 ,词表越大,训练越慢。
-
这个问题有两种主要解决方法
-
负采样
-
核心思想为:不再让模型从整个词表中选择正确词,而是让模型判断“这个词是不是当前上下文的真实目标词”。即将原来的 |V| 类分类问题,变成多个二分类问题。
-
举一个直观的例子
假设模型输入为:
我 爱 自然 语言
正确的输出是:
处理
全量 sotfmax 会问:
在整个词表里,下一个词是哪个?
它要比较:
处理、学习、苹果、…
整个词表全部都要算。
负采样则只问:
“处理”是不是正确词?
“学习”是不是正确词?
“苹果”是不是正确词?
训练目标是:
让真实词得分高,让负样本得分低
-
负采样训练的数学形式
-
-
Hierarchical Softmax
首先根据语料库收集每个词的词频,再用词频和词构建一个叶子结点个数为 V 的哈夫曼树
-